Meta’s looking to help AI researchers make their tools and processes more universally inclusive, with the release of a massive new dataset of face-to-face video clips, which include a broad range of diverse individuals, and will help developers assess how well their models work for different demographic groups.
Today we’re open-sourcing Casual Conversations v2 — a consent-driven dataset of recorded monologues that includes ten self-provided & annotated categories which will enable researchers to evaluate fairness & robustness of AI models.
— Meta AI (@MetaAI) March 9, 2023
More details on this new dataset ⬇️
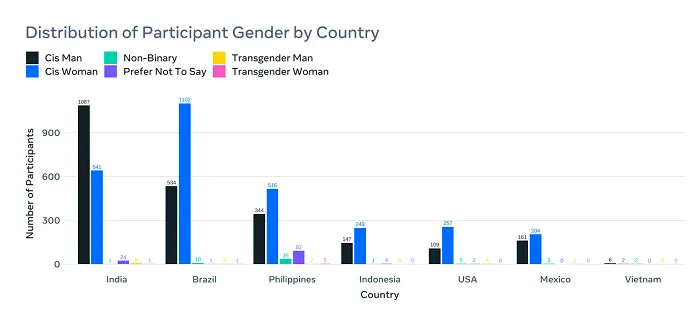
As you can see in this example, Meta’s Casual Conversations v2 database includes 26,467 video monologues, recorded in seven countries, and featuring 5,567 paid participants, with accompanying speech, visual, and demographic attribute data for measuring systematic effectiveness.
As per Meta:
“The consent-driven dataset was informed and shaped by a comprehensive literature review around relevant demographic categories, and was created in consultation with internal experts in fields such as civil rights. This dataset offers a granular list of 11 self-provided and annotated categories to further measure algorithmic fairness and robustness in these AI systems. To our knowledge, it’s the first open source dataset with videos collected from multiple countries using highly accurate and detailed demographic information to help test AI models for fairness and robustness.”
Note ‘consent-driven’. Meta is very clear that this data was obtained with direct permission from the participants, and was not sourced covertly. So it’s not taking your Facebook info or providing images from IG – the content included in this dataset is designed to maximize inclusion by giving AI researchers more samples of people from a wide range of backgrounds to use in their models.
Interestingly, the majority of the participants come from India and Brazil, two emerging digital economies, which will play major roles in the next stage of tech development.
The new dataset will help AI developers to address concerns around language barriers, along with physical diversity, which has been problematic in some AI contexts.
For example, some digital overlay tools have failed to recognize certain user attributes due to limitations in their training models, while some have been labeled as outright racist, at least partly due to similar restrictions.
That’s a key emphasis in Meta’s documentation of the new dataset:
“With increasing concerns over the performance of AI systems across different skin tone scales, we decided to leverage two different scales for skin tone annotation. The first is the six-tone Fitzpatrick scale, the most commonly used numerical classification scheme for skin tone due to its simplicity and widespread use. The second is the 10-tone Skin Tone scale, which was introduced by Google and is used in its search and photo services. Including both scales in Casual Conversations v2 provides a clearer comparison with previous works that use the Fitzpatrick scale while also enabling measurement based on the more inclusive Monk scale.”
It’s an important consideration, especially as generative AI tools continue to gain momentum, and see increased usage across many more apps and platforms. In order to maximize inclusion, these tools need to be trained on expanded datasets, which will ensure that everyone is considered within any such implementation, and that any flaws or omissions are detected before release.
Meta’s Casual Conversations data set will help with this, and could be a hugely valuable training set for future projects.
You can read more about Meta’s Casual Conversations v2 database here.

